Portkey 原生集成了您的 Vercel AI 应用。在本指南中,我们将创建一个 Vercel NextJS 应用,该应用使用 Portkey 路由到 200+ LLMs,并通过全栈可观察性、自动回退等功能使应用变得 强健 和 可靠。
指南:创建一个 Portkey + OpenAI 聊天机器人
继续创建一个 Next.js 应用,并将 ai 和 portkey-ai 安装为依赖项。
pnpm dlx create-next-app my-ai-app
cd my-ai-app
pnpm install ai portkey-ai
要将 OpenAI 集成到 Portkey 中,请将您的 OpenAI API 密钥添加到 Portkey 的虚拟密钥中
这将为您提供一个一次性密钥,您可以使用并轮换,而不是直接使用 OpenAI API 密钥
获取虚拟密钥和您的 Portkey API 密钥,并将它们添加到 .env 文件中:
PORTKEY_API_KEY="xxxxxxxxxx"
OPENAI_VIRTUAL_KEY="xxxxxxxxxx"
创建一个 Next.js 路由处理器,利用 Edge Runtime 生成聊天完成。将结果流回 Next.js。
在 app/api/chat/route.ts 创建一个路由处理器,调用 GPT-4,并接受一个包含字符串数组的 POST 请求:
Vercel AI SDK 提供了 OpenAIStream 函数,该函数解码 response 中的文本标记,并为简单消费进行适当编码。StreamingTextResponse 类工具扩展了 Node/Edge Runtime 的 Response 类,并带有默认头部。
Portkey 的签名与 OpenAI SDK 相同,但扩展了与 100+ LLMs 一起使用的功能。在这里,聊天完成调用将发送到 gpt-4 模型,响应将流式传输到您的 Next.js 应用程序。
从 OpenAI 切换到 Anthropic
Portkey 由一个 开源的通用 AI 网关 驱动,您可以使用相同的已知 OpenAI 规范路由到 200 多个 LLM。
让我们看看如何通过更新 2 行代码(而不破坏其他内容)将 GPT-4 切换到 Claude-3-Opus。
将您的 Anthropic API 密钥或 AWS Bedrock 秘密添加到 Portkey 的虚拟密钥中
在进行 /chat/completions 调用时更新模型名称
让我们看看实际操作:
同样,您只需将您的 Google AI Studio API 密钥 添加到 Portkey 并调用 Gemini 1.5:
其他提供商如 Azure、Mistral、Anyscale、Together 等也将遵循相同的步骤。
让我们创建一个 Client 组件,它将有一个表单来收集用户的提示并流式返回结果。useChat 钩子将默认使用我们之前创建的 POST 路由处理程序 (/api/chat)。不过,您可以通过向 useChat 传递 api 属性来覆盖这个默认值 ({ api: '...'})。
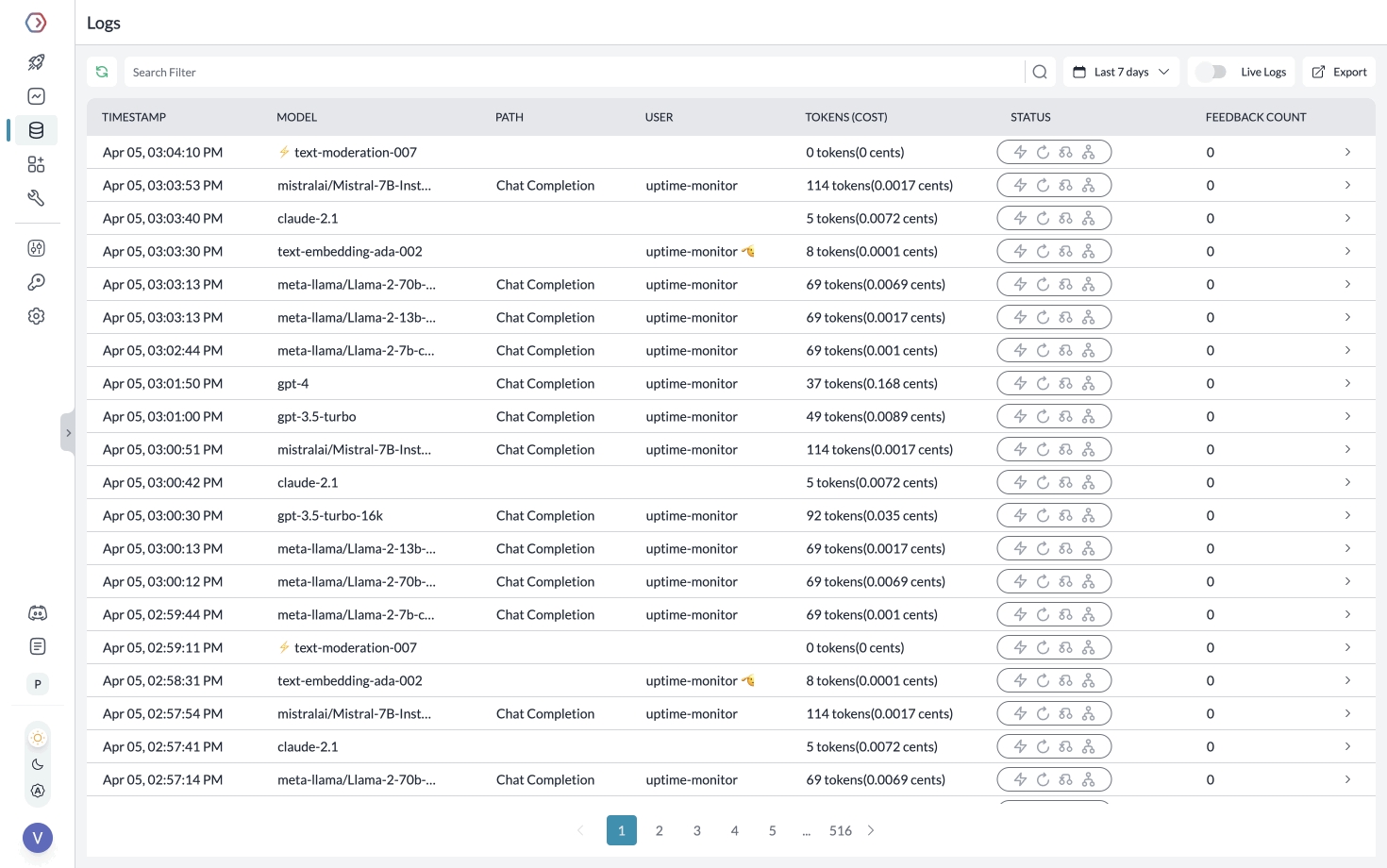
Portkey 记录您发送的所有请求,以帮助您调试错误,并获取请求级别 + 综合的成本、延迟、错误等方面的洞察。
您可以通过跟踪某些请求、传递自定义元数据或用户反馈来增强日志记录。
rolling logs and cachescreents 在 Portkey 中,进行 chat.completions 调用时,您可以传递任何 {"key":"value"} 对。Portkey 根据元数据对请求进行分段,以便为您提供详细的洞察。
了解更多关于 tracing 和 feedback。
指南:处理 OpenAI 失败情况
Portkey 帮助您在主要故障的情况下自动触发对任何其他 LLM/提供者的调用。创建一个使用 Portkey 的网关配置的后备逻辑。
例如,要设置从 OpenAI 到 Anthropic 的后备,网关配置将是:
您可以将此配置保存在 Portkey 应用中,并获得一个关联的配置 ID,您可以在实例化 Portkey 客户端时传递该 ID:
您可以将请求负载均衡到多个 LLM 或账户,以防止任何一个账户达到速率限制阈值。
例如,将请求路由到 1 个 OpenAI 和 2 个 Azure OpenAI 账户之间:
将此配置保存在 Portkey 应用中,并在实例化 Portkey 客户端时传递,就像我们上面所做的那样。
Portkey 还可以触发 自动重试、设置 请求超时 等功能。
Portkey 可以通过存储语义相似查询的响应并从缓存中提供服务,将 LLM 成本降低并将延迟减少 20 倍。
对于问答用例,缓存命中率高达 50%。要启用语义缓存,只需在您的网关配置中将 cache mode 设置为 semantic:
与上述相同,您可以在 Portkey 应用中保存您的缓存配置,并在实例化 Portkey 客户端时引用配置 ID。
此外,您可以设置缓存的 max-age 并强制刷新缓存。有关更多信息,请参阅 docs。
在代码中存储提示模板和说明会显得杂乱。使用 Portkey,您可以在一个地方创建和管理应用的所有提示,并直接访问我们的提示 API 获取响应。有关 Portkey 上的提示可以做什么 的更多信息。
要创建提示模板,
添加您的说明、变量,您可以修改模型参数,然后点击 Save
有关更多信息,请参阅 docs。
如果您有任何问题或疑虑,请通过 Discord 这里 联系我们。在 Discord 上,您还会遇到许多其他正在将他们的 Vercel AI + Portkey 应用投入生产的从业者。