从缓存返回重复请求
如果您的 GenAI 应用程序有多个用户触发相同或类似的查询到您的模型,从模型获取 LLM 响应可能会很慢且成本高。这是因为它需要从您的应用程序到模型进行多次往返,您可能最终会为重复查询付费。
为了避免这种不必要的 LLM 请求,您可以使用 Portkey 作为您的第一道防线。它非常有效,并且通过简单修改几行代码,可以在其支持的 100 多个 LLM 中发挥作用。
Portkey 缓存工作原理
所有启用缓存的请求将从 Portkey 的缓存中提供后续响应。
Portkey 提供两种主要的缓存技术供您在请求中启用——简单缓存和语义缓存。
简而言之:
简单缓存指的是对于相同的输入提示从缓存中提供服务。
语义缓存指的是使用相似性阈值(使用余弦相似度)从缓存中提供服务。
有关详细信息,请查看 这篇 博客文章。
1. 导入并认证 Portkey Client SDK
现在你对 Portkey 在缓存 LLM 响应方面的方法有了一个简要的思维导图。
让我们利用 Portkey Client SDK 发送聊天完成请求并附加网关配置,从而激活缓存。
要安装它,请在你的 NodeJS 环境中输入以下内容:
npm install portkey-ai实例化 Portkey 实例
此时,理解用 apiKey 和 virtualKey 参数实例化 portkey 实例是至关重要的。你可以在 Portkey Dashboard 中找到这两个参数的值。
访问参考文档以 获取 Portkey API 密钥 并了解 如何创建虚拟密钥。
2. 使用网关配置启用缓存
AI网关缓存您的请求,并根据请求头中的网关配置提供服务。这些配置是一个简单的JS对象或JSON字符串,包含以下键值对。
mode键指定您希望为应用程序使用的缓存策略。
接下来,使用Portkey SDK将这些配置附加到请求中。SDK接受一个config参数,可以作为参数接受这些配置。要了解更多方法,请参阅网关配置101。
3. 进行API调用,从缓存中服务
我们现在准备将迄今为止所学的知识付诸实践。我们计划向一个OpenAI模型(作为示例)发出两个请求,其中一个启用了简单缓存,而另一个启用了语义缓存。
而对于语义缓存,
在控制台上:
尝试重新措辞messages数组中的提示,看看您是否注意到接收响应的时间或响应质量的任何差异。
您可以按需刷新缓存吗?可以的!
您可以控制缓存保持活动的时间吗?当然可以!
请查看文档,了解控制LLM响应缓存的所有可用功能。
4. 查看分析和日志
在 Analytics 页面,您可以在缓存选项卡下找到 Portkey 的缓存性能分析。
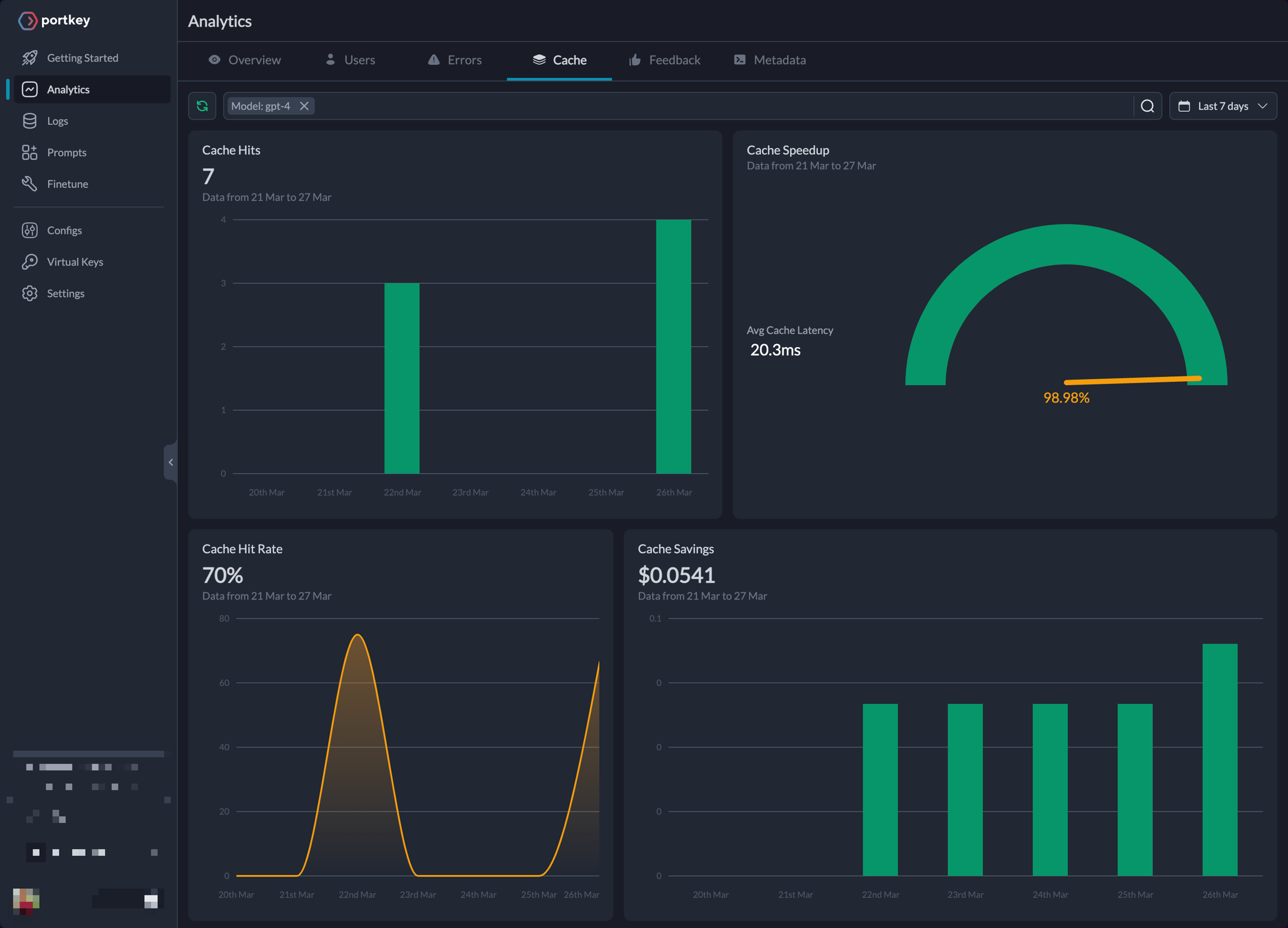
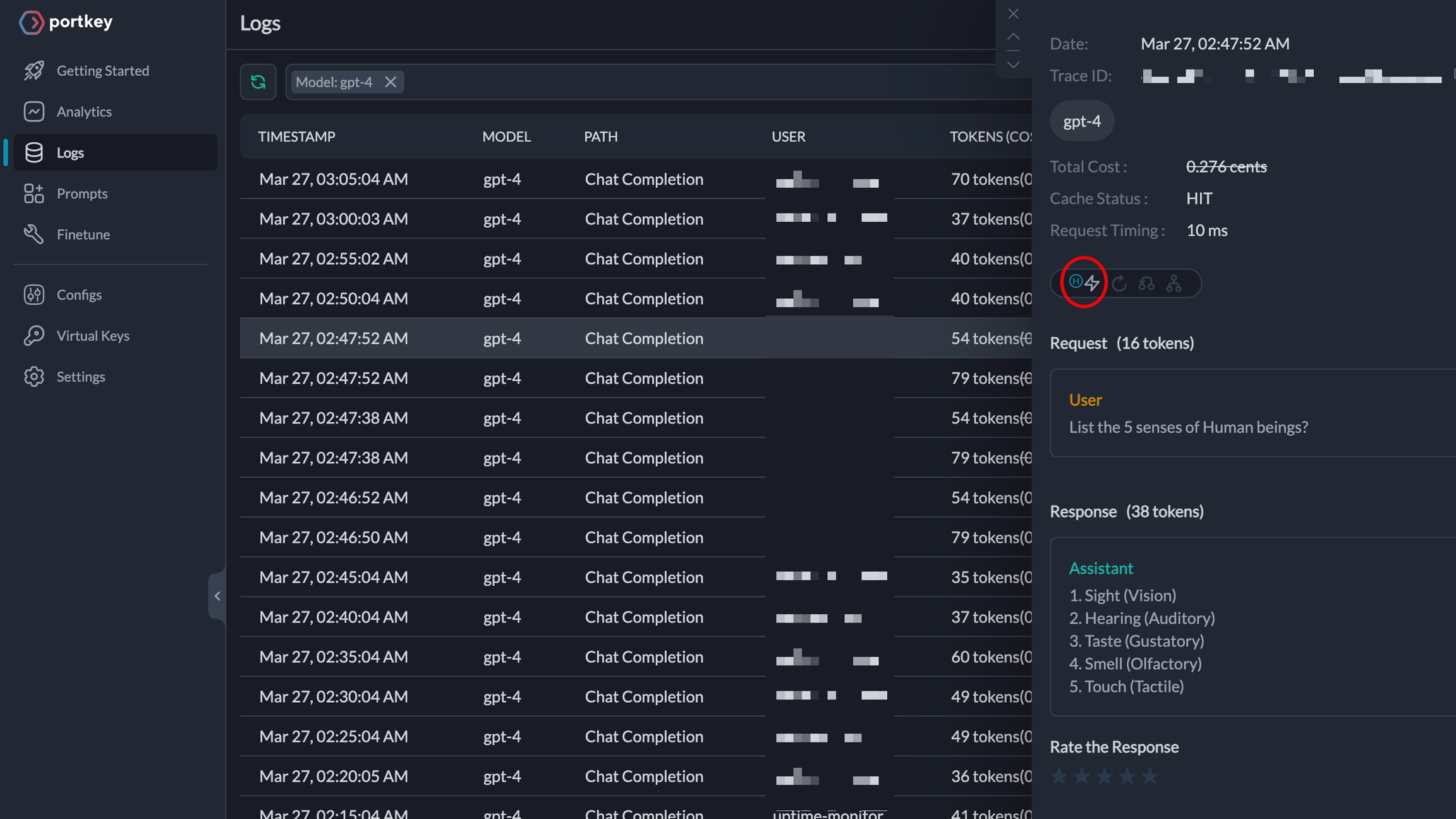
Logs 页面显示了从缓存中提供响应的 LLM 调用列表。当缓存命中时,相应的图标会被激活。
下一步
通过利用简单和语义缓存,您可以避免不必要的 LLM 请求,减少延迟,并提供更好的用户体验。因此,请在您自己的项目中尝试使用 Portkey Cache——好处就在几行代码之内!
一些实验建议:
尝试使用 Portkey UI 中的配置作为参考。
Last updated