使用 Supabase pgvector 和 Portkey 构建文章推荐应用
考虑到您有一系列支持文章,希望在用户搜索时向他们推荐。您希望尽可能提供最佳匹配。随着大型语言模型(LLMs)和向量数据库等工具的出现,建议和推荐系统的方法已经显著演变。
在本文中,我们将创建一个简单的 NodeJS 应用程序,该应用程序存储 支持文章(仅标题,为了简单起见),并通过其嵌入执行向量相似性搜索,向用户返回最佳文章。
快速免责声明:
本文旨在为您提供一张地图,帮助您入门并导航类似问题的解决方案。
如果您有兴趣开始代码修改,请在 此 Repl 上探索代码库。
什么使得向量相似性特别?
简短回答:嵌入。
将一段内容转换为向量表示的技术称为嵌入。它们允许您从数学上分析语义内容。

LLM能够将我们的内容转换为向量表示,并将其嵌入到向量空间中,基于两个嵌入之间的距离得出相似性。这些嵌入将存储在向量数据库中。
在本文中,我们将使用Supabase并启用pgvector来存储向量。
应用概述
我们的应用将利用 Supabase 向量数据库以嵌入的形式维护文章。在接收到新的查询时,数据库将智能地推荐最相关的文章。
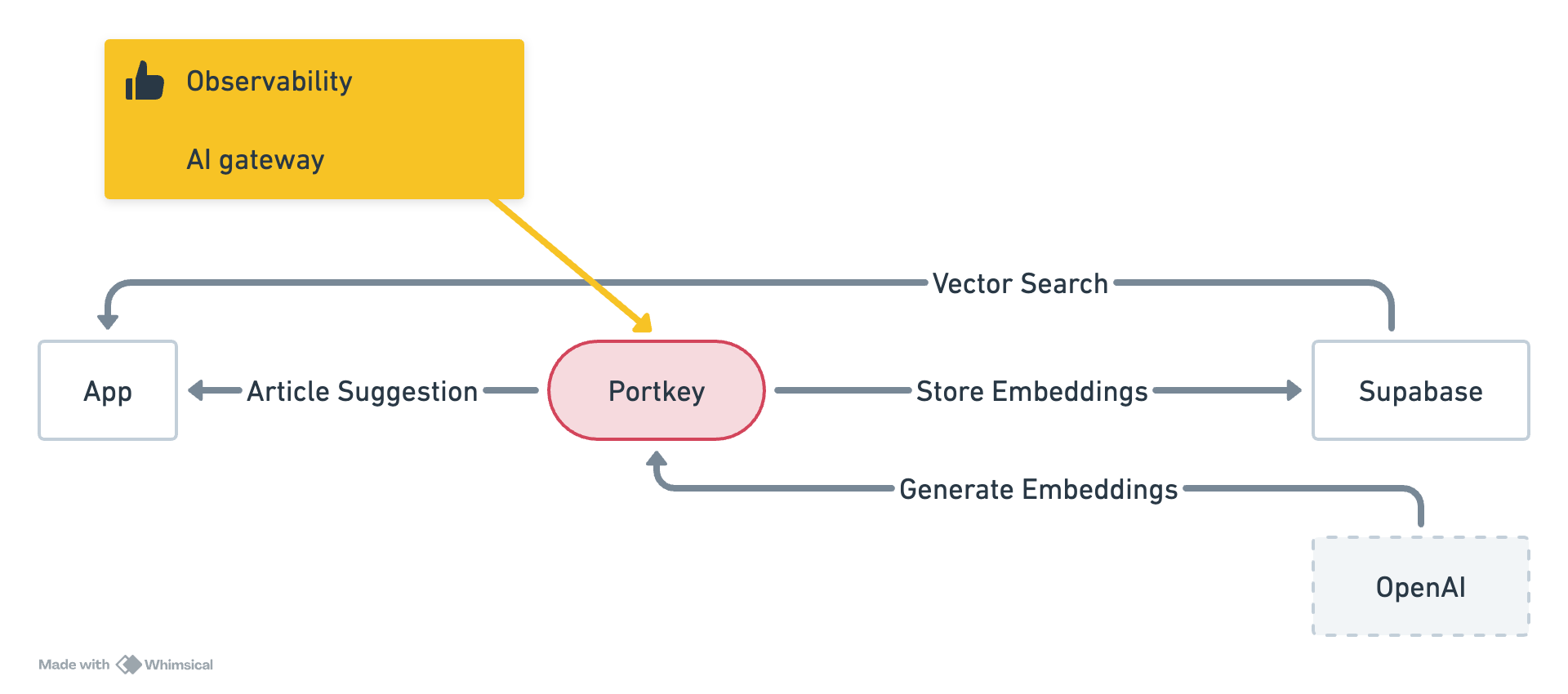
以下是该过程的工作方式:
应用将读取包含文章标题列表的文本文件。
然后,它将通过 Portkey 使用 OpenAI 模型将内容转换为嵌入。
这些嵌入将存储在 pgvector 中,并附带一个启用相似性匹配的函数。
当用户输入新的查询时,应用将根据相似性匹配数据库函数返回最相关的文章。
设置
通过设置本教程的三件事开始 — NodeJS 项目、Portkey 和 Supabase。
Portkey
注册并登录到 Portkey 控制台。
复制您的 OpenAI API 密钥并将其添加到 Portkey Vault。
这将为您提供一个唯一标识符,即虚拟密钥,您可以在代码中引用它。稍后会详细介绍。
Supabase
前往 Supabase 创建一个 新项目。给它一个您选择的名称。我将其标记为“产品维基”。此步骤将提供访问密钥,例如 项目 URL 和 API 密钥。请保存它们。
项目已准备就绪。
我们希望将嵌入存储在您的数据库中。要使数据库能够存储嵌入,您必须从 仪表板 > 数据库 > 扩展 启用 向量 扩展。
NodeJS
导航到您希望的任何目录并运行
查看使用 package.json 创建的项目文件。由于我们希望将文章列表存储到数据库中,因此我们必须从文件中读取它们。创建 articles.txt 并复制以下内容:
打开 index.js,您已准备就绪。让我们开始编写代码。
第一步:导入和认证 Portkey 和 Supabase
由于我们的应用程序将与 OpenAI(通过 Portkey)和 Supabase pgvector 数据库进行交互,因此让我们导入必要的 SDK 客户端以便对它们进行操作。
fs 用于帮助我们从 articles.txt 文件中读取文章列表,而 USER_QUERY 是我们将用于进行相似性搜索的查询。
第2步:创建表
我们可以使用 SQL 编辑器执行 SQL 查询。这个项目将有一个表,我们称之为 support_articles 表。它将存储文章的 title 及其嵌入。请随意添加您选择的更多字段,例如描述或标签。
为了简单起见,创建一个包含 ID、content 和 embedding 列的表。
在 SQL 编辑器中执行上述 SQL 查询。
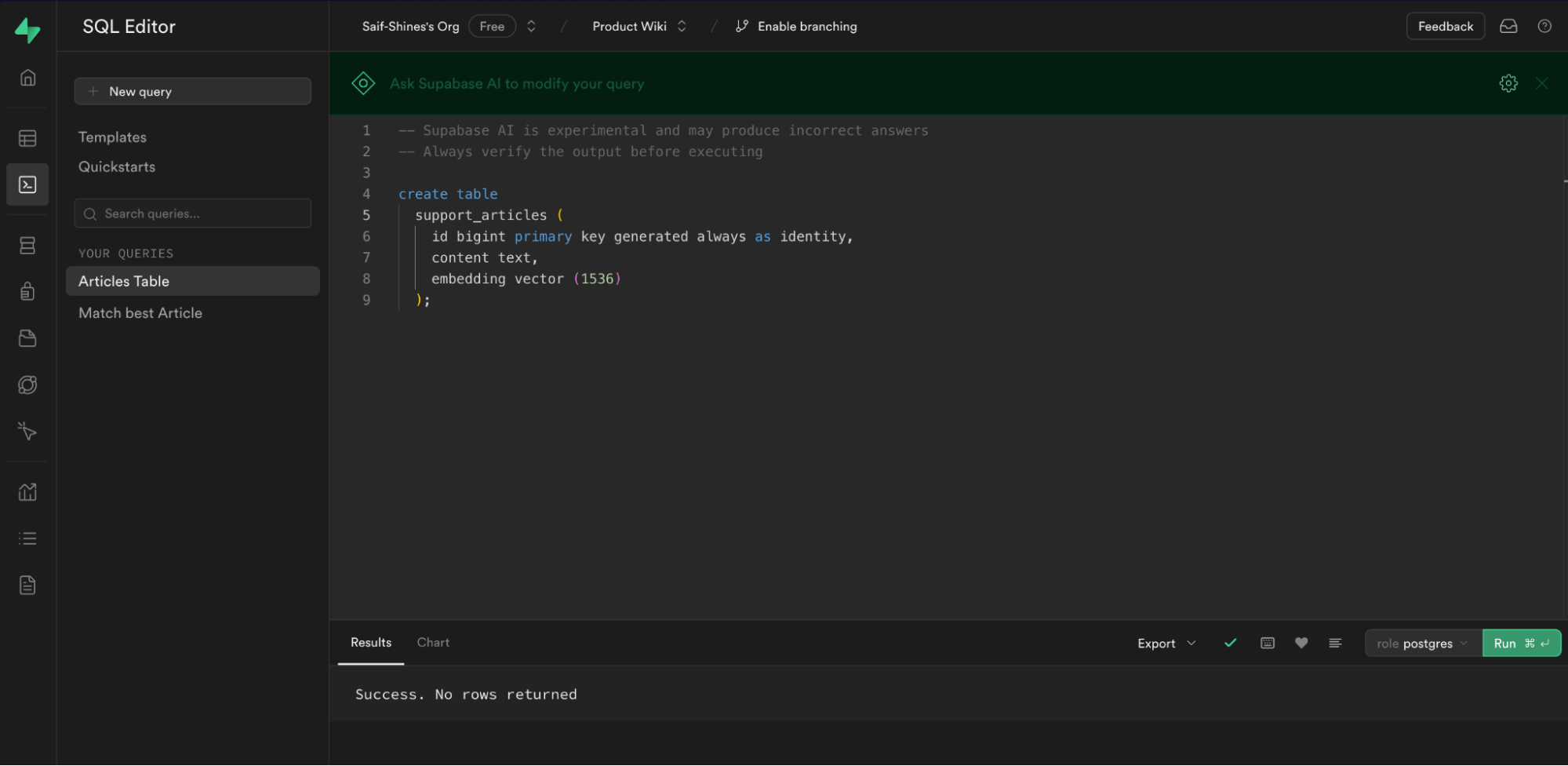
您可以通过导航到 Database > Tables > support_articles 验证表是否已创建。一旦执行成功,结果选项卡中将出现成功消息。
第 3 步:读取、生成和存储嵌入
我们将使用 fs 库读取 articles.txt 并将列表中的每个标题转换为嵌入。使用 Portkey,生成嵌入非常简单,和使用 OpenAI SDK 一样,不需要额外的代码更改。
同样,将嵌入存储到 Supabase:
将所有内容整合在一起——从文件中读取,生成嵌入,并将其存储到 Supabase。
就这样!—— 您只需编写一行代码即可将所有项目存储到 pgvector 数据库中。
await storeSupportArticles();
您现在应该可以在表编辑器中看到创建的行。
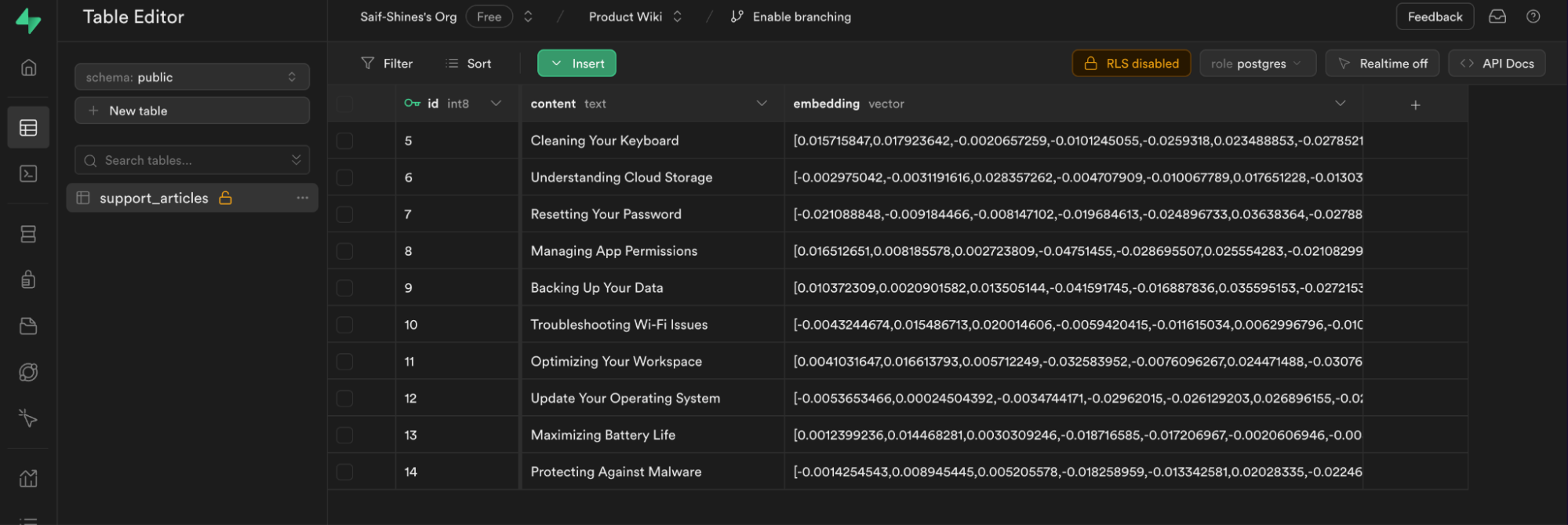
第4步:创建一个数据库函数以查询相似匹配
接下来,让我们设置一个 数据库函数 来使用 Supabase 进行向量相似性搜索。这个数据库函数将以 用户查询向量 作为参数,并返回一个包含 id、content 和与数据库中最佳行及用户查询的 similarity 分数的对象。
在 SQL 编辑器中执行它,类似于创建表。
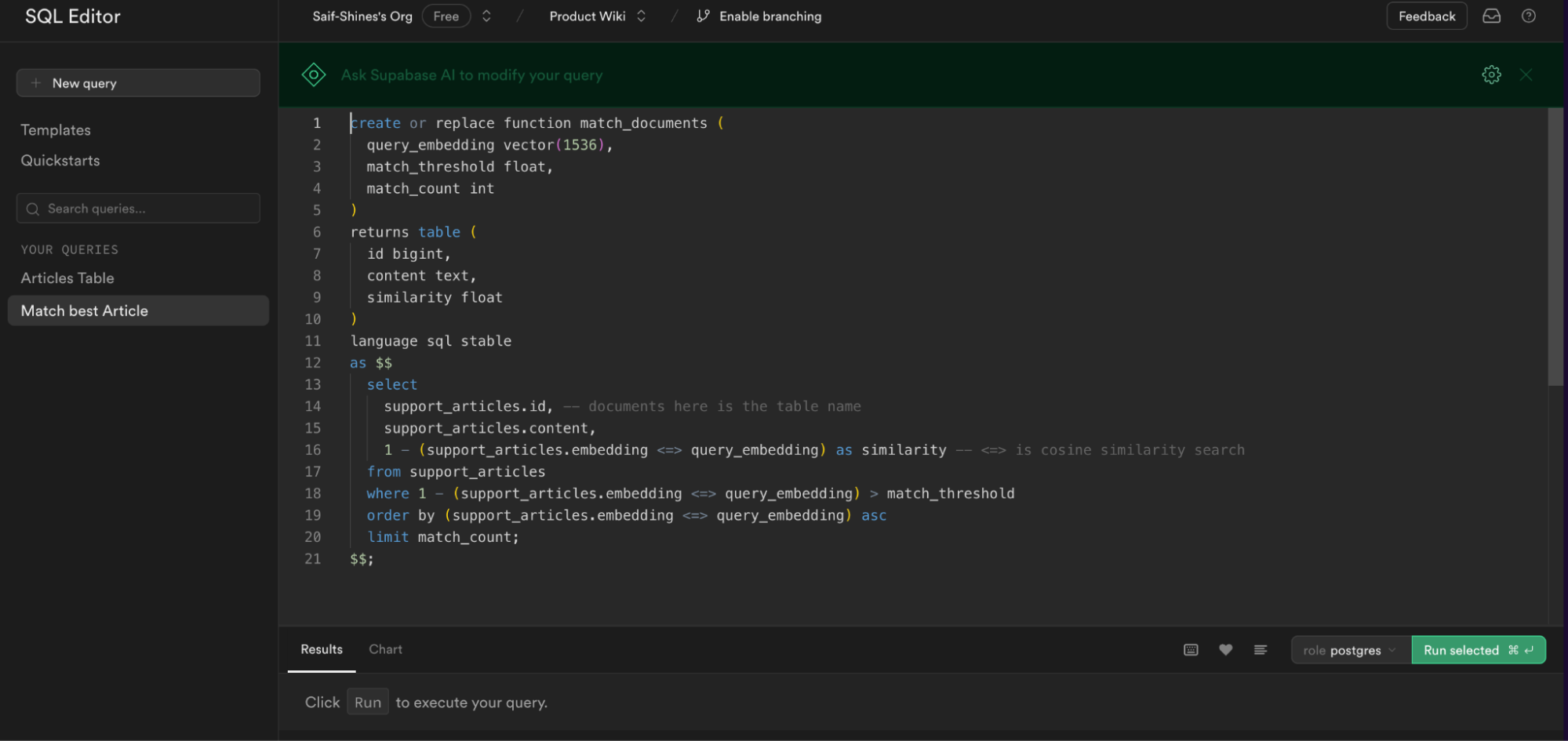
恭喜,现在我们的 support_articles 已经能够返回向量相似性搜索操作。
不再等待!让我们运行一个搜索查询。
第5步:查询相似匹配
supabase 客户端可以进行远程过程调用,以调用我们的向量相似性搜索功能,找到与用户查询最接近的匹配项。
参数将与我们在创建数据库函数时声明的参数匹配(在第4步中)。
控制台日志
后记
一个与上述用户查询最佳匹配的单个查询耗费了 6 个 tokens,费用大约为 $0.0001 美分。在开发这个应用的过程中,我使用了 2.4k tokens,平均延迟为 383ms。
你可能会想,我是怎么知道这些的?这全都要感谢 Portkey Dashboard。
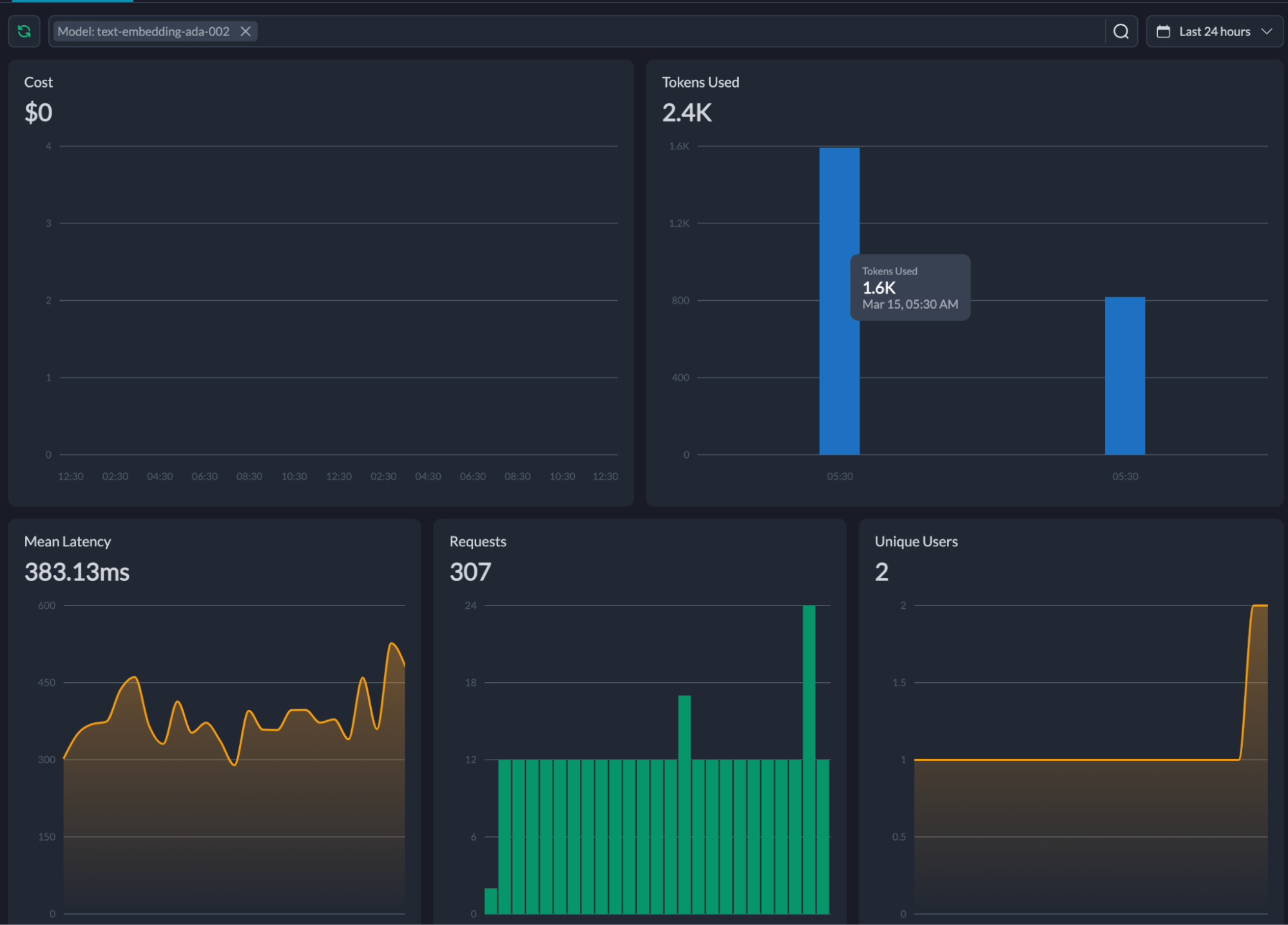
这些信息非常有价值,特别是在实时生产中使用时。我鼓励你考虑在正在进行的项目中实现搜索用例,例如推荐、建议和类似项目。
恭喜你走到这一步!你现在知道如何在开发中使用嵌入并监控你的应用在生产中的表现。
Last updated